
看穿机器学习(W-GAN模型)的黑箱
2017-03-01 by:CAE仿真在线 来源:互联网
图a. Principle of GAN.
这学期,老顾在讲授一门研究生水平的数字几何课程,目前讲到了2016年和丘成桐先生、罗锋教授共同完成的一个几何定理【3】,这个工作给出了经典亚历山大定理(Alexandrov Theorem)的构造性证明,也给出了最优传输理论(Optimal Mass Transportation)的一个几何解释。
这几天,机器学习领域的Wasserstein GAN突然变得火热,其中关键的概念可以完全用我们的理论来给出几何解释,这允许我们在一定程度上亲眼“看穿”传统机器学习中的“黑箱”。
下面是老顾下周一授课的讲稿。
训练模型 生成对抗网络GAN (Generative Adversarial Networks)是一个“自相矛盾”的系统,就是以己之矛克以己之盾,在矛盾中发展,使得矛更加锋利,盾更加强韧。这里的矛被称为是判别器(Descriminator),这里的盾被称为是生成器(Generator)。
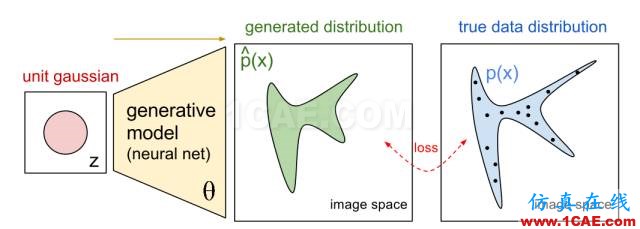
图b. Generative Model.
生成器G一般是将一个随机变量(例如高斯分布,或者均匀分布),通过参数化的概率生成模型(通常是用一个深度神经网来进行参数化),进行概率分布的逆变换采样,从而得到一个生成的概率分布。判别器D也通常采用深度卷积神经网。
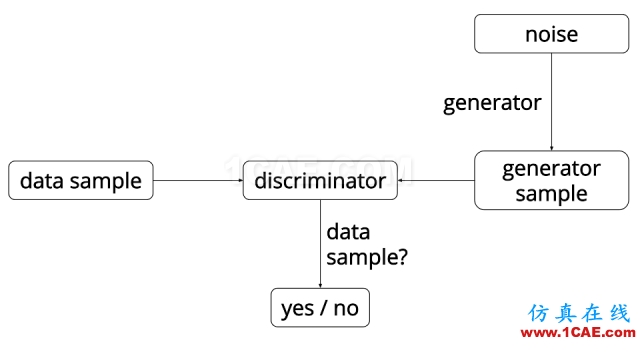
图1. GAN的算法流程图。
矛盾的交锋过程如下:给定真实的数据,其内部的统计规律表示为概率分布

,我们的目的就是能够找出

,我们希望
尽量接近
。为了区分真实概率分布
和生成概率分布

。
第一项不依赖于生成器G, 此式也可以定义GAN中的生成器的损失函数。
在训练中,判别器D和生成器G交替学习,最终达到纳什均衡(零和游戏),判别器无法区分真实样本和生成样本。
优点 GAN具有非常重要的优越性。当真实数据的概率分布不可计算的时候,传统依赖于数据内在解释的生成模型无法直接应用。但是GAN依然可以使用,这是因为GAN引入了内部对抗的训练机制,能够逼近一下难以计算的概率分布。更为重要的,Yann LeCun一直积极倡导GAN,因为GAN为无监督学习提供了一个强有力的算法框架,而无监督学习被广泛认为是通往人工智能重要的一环。
缺点 原始GAN形式具有致命缺陷:判别器越好,生成器的梯度消失越严重。我们固定生成器G来优化判别器D。考察任意一个样本


两边对


代入生成器损失函数,我们得到所谓的Jensen-Shannon散度(JS)

。
在这种情况下(判别器最优),如果

改进 本质上,JS散度给出了概率分布
为此,我们引入最优传输的几何理论(Optimal Mass Transportation),这个理论可视化了W-GAN的关键概念,例如概率分布,概率生成模型(生成器),Wasserstein距离。更为重要的,这套理论中,所有的概念,原理都是透明的。例如,对于概率生成模型,理论上我们可以用最优传输的框架取代深度神经网络来构造生成器,从而使得黑箱透明。
给定欧氏空间中的一个区域

,上面定义有两个概率测度

和

,满足

,
我们寻找一个区域到自身的同胚映射(diffeomorphism),

, 满足两个条件:保持测度和极小化传输代价。
保持测度 对于一切波莱尔集

,

换句话说映射T将概率分布
映射成了概率分布
,记成

。直观上,自映射

,带来体积元的变化,因此改变了概率分布。我们用
和
来表示概率密度函数,用


,

,
这被称为是雅克比方程(Jacobian Equation)。
最优传输映射 自映射
的传输代价(Transportation Cost)定义为

在所有保持测度的自映射中,传输代价最小者被称为是最优传输映射(Optimal Mass Transportation Map),亦即:

,
最优传输映射的传输代价被称为是概率测度
和概率测度
之间的Wasserstein距离,记为

。
在这种情形下,Brenier证明存在一个凸函数

,其梯度映射

就是唯一的最优传输映射。这个凸函数被称为是Brenier势能函数(Brenier potential)。
由Jacobian方程,我们得到Brenier势满足蒙日-安培方程,梯度映射的雅克比矩阵是Brenier势能函数的海森矩阵(Hessian Matrix),

。
蒙日-安培方程解的存在性、唯一性等价于经典的凸几何中的亚历山大定理(Alexandrov Theorem)。
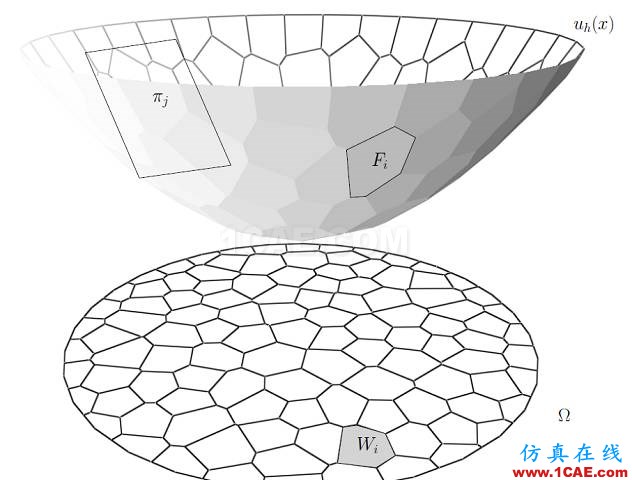
图2. 亚历山大定理。
亚历山大定理 如图2所示,给定平面凸区域

,考察一个开放的凸多面体

,选定一个面

,
的法向量记为

,
的投影和



凸多面体可以被

后面,我们可以看到,这个凸多面体就是Brenier势能函数,其梯度映射将一个概率分布

映到另外一个概率分布

Wasserstein-GAN模型中,关键的概念包括概率分布(概率测度),概率测度间的最优传输映射(生成器),概率测度间的Wasserstein距离。下面,我们详细解释每个概念所对应的构造方法,和相应的几何意义。
概率分布 GAN模型中有两个至关重要的概率分布(probability measure),一个是真实数据的概率分布

,一个是生成数据的概率分布


图3. 由保角变换(conformal mapping)诱导的圆盘上概率测度。
概率测度可以看成是一种推广的面积(或者体积)。我们可以用几何变换随意构造一个概率测度。如图3所示,我们用三维扫描仪获取一张人脸曲面,那么人脸曲面上的面积就是一个概率测度。我们缩放变换人脸曲面,使得总曲面等于

我们可以将以上的描述严格化。人脸曲面记为

,其上具有黎曼度量

。平面圆盘记为

,平面坐标为

,平面的欧氏度量为

。保角映射记为

则

,这里面积变换率函数

给出了概率密度函数。

诱导了圆盘
上的一个概率测度

。

图4. 两个概率测度之间的最优传输映射。
最优传输映射 圆盘上本来有均匀分布


,则存在唯一的最优传输映射

。图4显示了这个映射

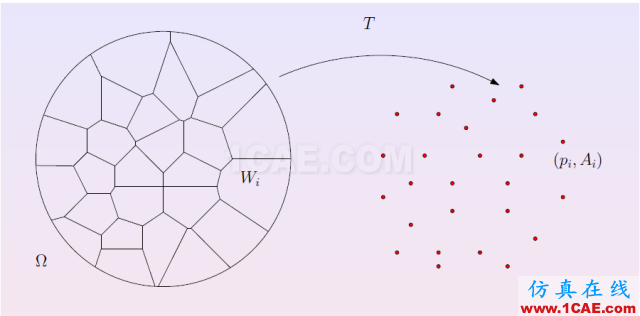
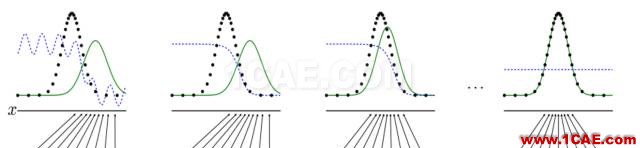
图5. 离散最优传输。
离散最优传输映射 最优传输映射的数值计算非常几何化,因此可以直接被可视化。我们将目标概率测度离散化,表示成一族离散点,

;每点被赋予一个狄拉克测度,

,满足

。然后,我们求得单位圆盘的一个胞腔分解,

,每个胞腔

映到相应的目标点

,

。映射保持概率测度,胞腔的面积等于目标测度,

同时极小化传输代价,

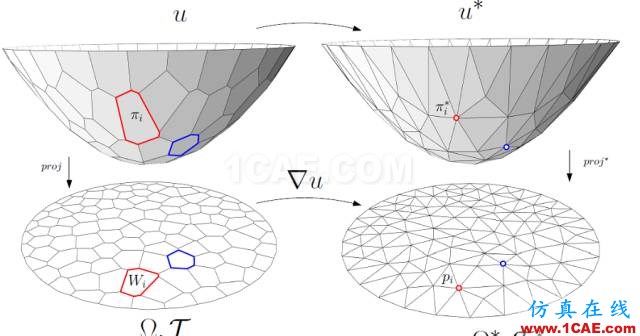
图6. 离散Brenier势能函数,离散最优传输映射。
离散Brenier势能 离散最优传输映射是离散Brenier势能函数的梯度映射。对于每一个目标离散点
,我们构造一个平面

,这里平面的截距

的图(Graph),

。
图6左侧显示了离散Briener势能函数。凸多面体在平面上的投影构成了平面的胞腔分解,凸多面体的每个面

被映成了一个胞腔
;每个面
的梯度都是
,因此Brenier势能函数的梯度映射就是

。
根据保测度性质,每个胞腔
的面积应该等于指定面积

。由此,我们调节平面的截距

离散Wasserstein距离 我们和丘成桐先生建立了变分法来求取平面的截距

。给定截距向量

,平面族为

,其上包络构成的Briener势能函数为

, 上包络的投影生成了平面的胞腔分解

, 胞腔的面积记为

。我们定义的能量为,

这个能量在子空间


图7给出了柱体体积的可视化,柱体体积

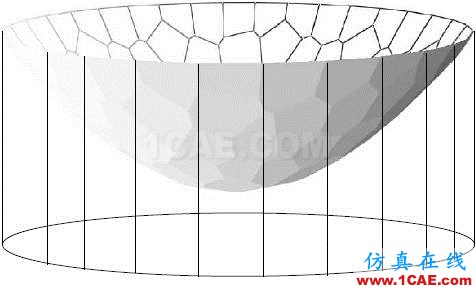
图7. 离散Brenier势能函数的图截出的柱体体积
。
体积函数
,其图



,函数的切线的斜率为y,则此切线的截距满足

,
这被称为是函数
的勒让德变换。

以切线的斜率为参数,以切线的截距为函数值。
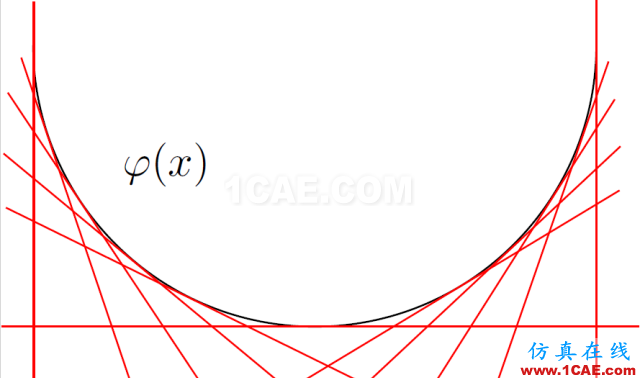
图8.凸函数的图像由其切线包络而成,切线集合被表示成原函数的勒让德对偶。
因为
的凸性,映射

是微分同胚,记为

。那么,原函数和勒让德变换后的函数满足关系:

,
这里c,d是常数。原函数和其勒让德变换的直观图解由图9给出。我们在xy-平面上画出曲线
,曲线下面的面积是
,曲线上面的面积是勒让德变换
。
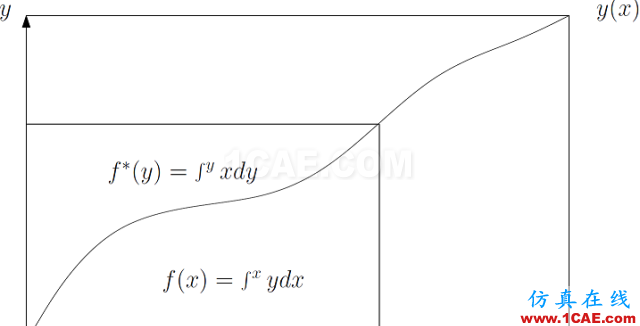
图9. 图解勒让德变换。
勒让德变换的几何图景对任意维都对。我们下面来考察体积函数
的勒让德变换

。根据定义,

,
假如我们变动截距
,或者等价地变动胞腔面积

,考察两个胞腔交界处

,

,
p本来属于

,变化后属于
,所有这种点的总面积为

。则为Wasserstein距离带来的变化是:

因此,总的Wasserstein距离的变化是

。
由此我们看到Wasserstein距离等于

,
其非线性部分是柱体积的勒让德变换。
通过以上讨论,我们看到给定两个概率分布

,则存在唯一的一个凸函数(Brenier 势函数)
,其梯度映射

把一个概率分布

在Wasserstein-GAN模型中,通常生成器和判别器是用深度神经网络来实现的。根据最优传输理论,我们可以用Briener势函数来代替深度神经网络这个黑箱,从而使得整个系统变得透明。在另一层面上,深度神经网络本质上是在训练概率分布间的传输映射,因此有可能隐含地在学习最优传输映射,或者等价地Brenier势能函数。对这些问题的深入了解,将有助于我们看穿黑箱。

图10. 基于二维最优传输映射计算的曲面保面积参数化(area preserving parameterization),苏政宇作。

图11. 基于三维最优传输映射计算的保体积参数化 (volume preserving parameterization),苏科华作。
(在2016年,老顾撰写了多篇有关最优传输映射的博文,非常欣慰地看到这些文章启发了一些有心的学者,发表了SIGGRAPH论文,申请了NSF基金。感谢大家关注老顾谈几何,希望继续给大家灵感。)
[1]Arjovsky, M. & Bottou, L.eon (2017) Towards Principled Methods for Training Generative Adversarial Networks
[2] Arjovsky, M., Soumith, C. & Bottou, L.eon (2017) Wasserstein GAN.
[3] Xianfeng Gu, Feng Luo, Jian Sun and Shing-Tung Yau, Variational Principles forMinkowski Type Problems, Discrete Optimal Transport, and Discrete Monge-Ampere
Equations, Vol. 20, No. 2, pp. 383-398, Asian Journal of Mathematics (AJM), April 2016.
相关标签搜索:看穿机器学习(W-GAN模型)的黑箱 有限元技术培训 有限元仿真理论研究 有限元基础理论公式 能量守恒质量守恒动量守恒一致性方程 有限体积法 什么是有限元 有限元基础知识 有限元软件下载 有限元代做 Fluent、CFX流体分析 HFSS电磁分析 Ansys培训




